当一个名为“Quasar Alpha”的神秘模型跳入现场时,我公开宣布这很可能是 OpenAI 最新的旗舰模型。虽然我错误地称它为“GPT-5”,但我 100% 正确,这确实是 OpenAI 的最新模型。
前不久,“GPT-4.1”正式发布,这些模型的有效性令人发指。然而,没有讨论的是它对各地数据分析师的现实影响。
什么是 GPT-4.1?
GPT-4.1 系列是 OpenAI API 中提供的三个新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。
这些模型几乎在所有方面都优于 GPT-4o 和 GPT-4o mini,尤其是在编码和指令跟随方面。它们还具有更大的上下文窗口 — 支持多达 100 万个token —并且实际上能够使用整个窗口。
然而,对于任何新模型,我不一定相信它们的创造者对他们性能的评价。我喜欢亲自测试它们。
Google 和 OpenAI 之间争夺“最佳 AI 模型”
2024 年,OpenAI 系列模型被认为是最好的。这种情况在 2025 年发生了翻天覆地的变化。
- DeepSeek R1 以首创的廉价 “推理” 模型抢尽风头;
- xAI 发布了 Grok,这是另一个非常有效的模型,特别是对于搜索或推理任务;
- Google 发布了 Gemini Flash2,它的性能优于所有其他主要的大型语言模型而价格只是其中的一小部分;
- Anthropic 发布了 Claude 3.7Sonnet,就原始性能而言,它是世界上最好的 AI模型之一;
随着所有这些版本的发布,GPT-4 失去了“最佳 AI 模型”的称号。该头衔属于 Anthropic(凭借 Claude 3.7 Sonnet 的原始功能)和 Google(凭借 Gemini Flash 2.0 的成本效益)。
在复杂推理任务中测试所有其他大型语言模型
为了测试这些模型的有效性,我在一项复杂的推理任务中对每个大型语言模型进行了测试,该任务的重点是用于财务分析的 SQL 查询生成。这项任务涉及向每个模型询问 60 个财务问题,并让模型生成能够正确回答这些问题的 SQL 查询。
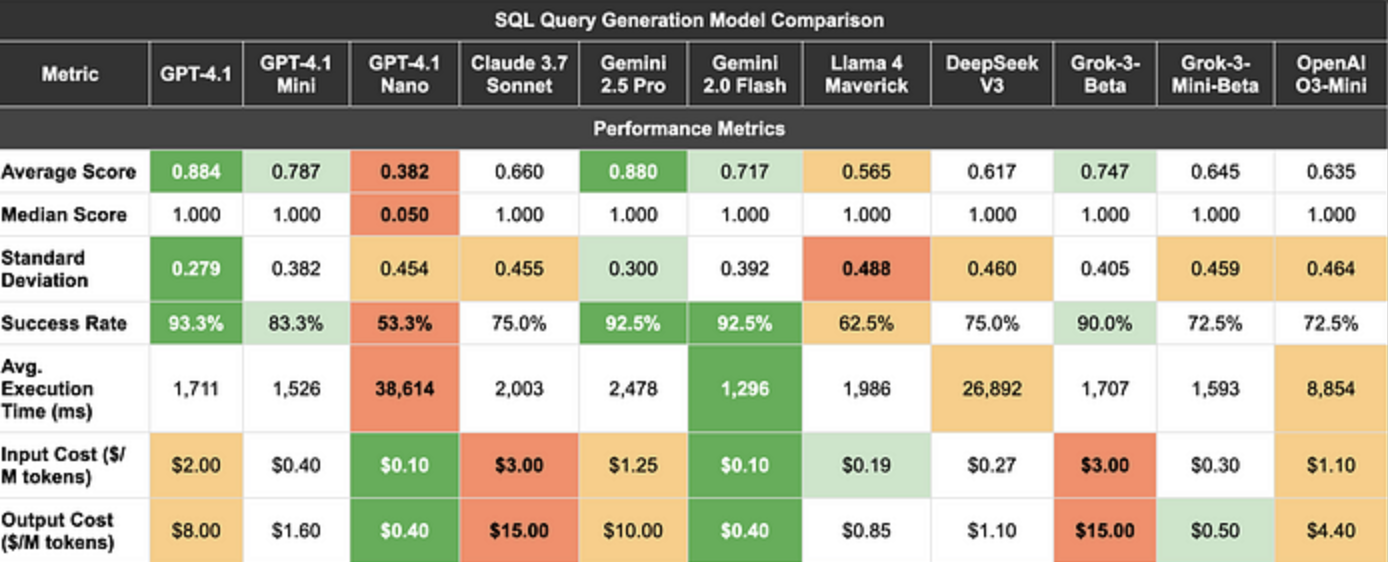
GPT-4.1 的成功率最高,为 93.3%,平均分最高,为 0.884,以微弱优势超过双子座 2.5 Pro 的 92.5% 成功率和 0.880 的平均分。
特别有趣的是性价比平衡。虽然 GPT-4.1 以高价位(每百万token 2.00 美元输入/8.00 美元输出)提供最佳原始性能,但它与 Gemini 2.5 Pro(1.25 美元/10.00 美元)的价格段相似。
将此与以前的“世界上最好的模型”(Claude 3.7 Sonnet)相比,Google 和 OpenAI 毫不费力地赢得了这个奖项。它们在成本、速度和原始性能方面更好。